

In the early days of LLMs, people loved using the "wolf, goat, cabbage" logic puzzle to test them. It's a pretty simple puzzle and it's so well known that it was part of the training data of all models. So GPT-2 and (I think even 3?) would always say "take the goat across first" even if you messed with the variables to make that not be the solution.
I still like using this to get a feel for models. Most of the newer ones figure out if you're trying to trick them now, but that doesn't mean they can actually solve it once its been changed (e.g. by swapping the goat and cabbage in the definition so the goat eats the cabbage and the cabbage eats the wolf).
Kimi 2.6 came out today and I saw a bunch of buzz about how good it is, with some people claiming "Opus-level performance". This is not a scientific benchmark, but it's a good basic vibe check to see how easy it is to trick a model, and to look at how it tries to do basic reasoning.
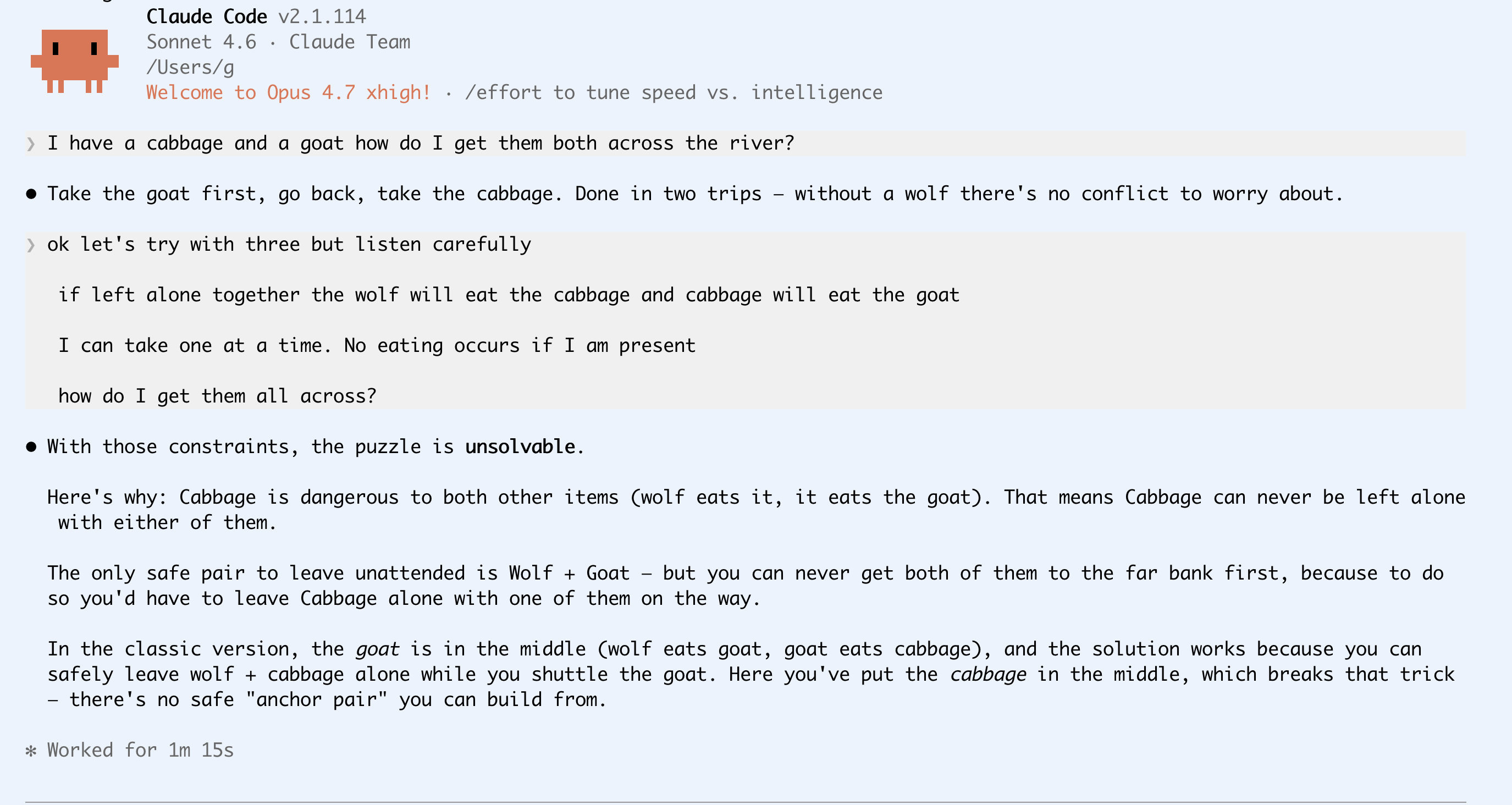
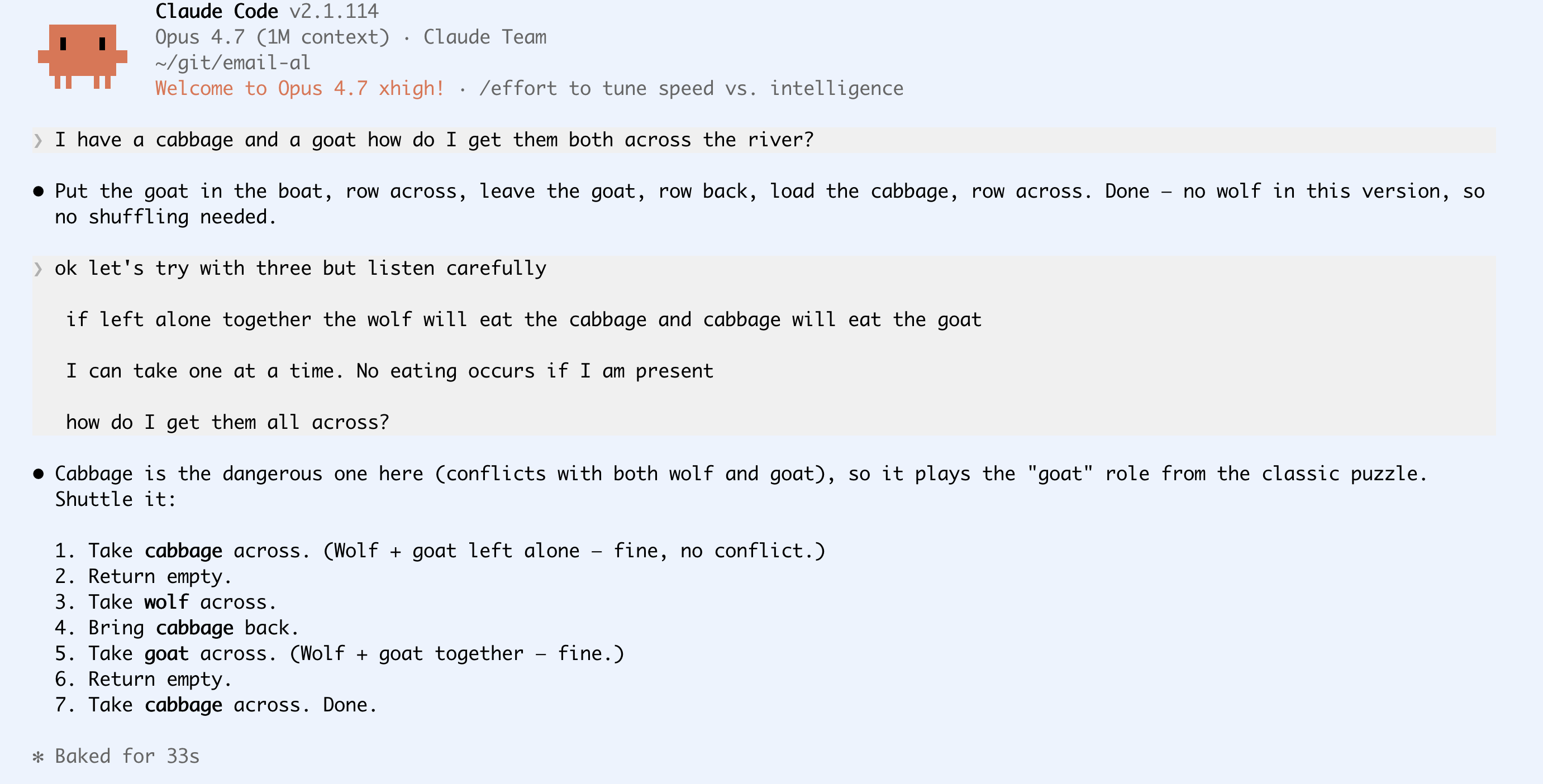
Spoilers: Opus 4.7 solves it easily. Both Sonnet 4.6 and Kimi 2.6 go into some kind of infinite-logic loop and try all the variations before declaring that its impossible.
The prompts
For each model, I gave the same two prompts in a clean context
First:
I have a cabbage and a goat how do I get them both across the river?
This is missing most of the key information you'd need to make it a real puzzle, but it sets a good baseline to see if they immediately reach for the training data or think about it from just the information provided.
Then:
ok let's try with three but listen carefully
if left alone together the wolf will eat the cabbage and cabbage will eat the goat
I can take one at a time. No eating occurs if I am present
how do I get them all across?
Kimi 2.6
Kimi thinks for a very long time for both questions. Even for the warm up question with only a cabbage and a goat it gets lost a bunch in its thinking space but eventually figures out that the problem is simpler than it seems and gives the correct answer.
Then for the real question it thinks for even longer, trying to do full-on constraint satisfaction modelling, but still failing on every path it tries (even the correct one when it happens on it by chance is declared wrong).

Here's the full transcript.
Sonnet 4.6
Sonnet similarly thinks for a long time. I think we can't see all the reasoning token output any more in Claude Code? Or maybe it's configurable? I battle to keep up to be honest, but anyway this is what I saw. Note the 1m 15s at the bottom.
Opus 4.7
Finally here's Opus 4.7. No nonsense, direct answer and much faster response indicating that it probably didn't get sidetracked trying to model out every combination. Less than half the time of Sonnet and the correct answer.
I've been default to Sonnet in day-to-day work as Opus seems to crush my limits so fast, but this makes me think I should try Opus more - maybe I'll get more done in less time.