
How to Do an Agent Experience Audit
If you've read What Is Agent Experience and Why Should You Care? you already know that agent experience (AX) is the new developer experience — and that if AI coding agents can't find, understand, and use your platform, you're invisible to a growing portion of the developer market.
The natural follow-up question is: how do you actually measure it?
The obvious answer — ask an agent to audit your own AX — turns out not to work. Agents are good at following instructions about things they already know, but an AX audit requires forming a judgment about what an agent doesn't know, what it would do when nobody is watching, and where it would get stuck before a human could intervene. That's harder to simulate than it sounds. The agent you're asking is the same one you're auditing, and it doesn't have a clean way to pretend it hasn't seen your documentation.
What actually works is running structured tests with fresh agent sessions and grading the results against a consistent rubric.
The four phases
We break an AX audit into four phases:
| Phase | Question |
|---|---|
| Discoverability | Can an agent find you? |
| Onboarding | Can an agent get started with minimal human help? |
| Integration | Can an agent set up a working hello-world equivalent? |
| Agent tooling | If you have MCP servers, Skills, or similar — do they actually help? |
Each phase gets a score from 1 to 4:
- 4/4 — Working as expected; no significant friction
- 3/4 — Mostly works; minor gaps
- 2/4 — Partial; significant friction or gaps
- 1/4 — Broken or absent
We'll work through all four phases using Kestra, an open-source event-driven workflow orchestration platform, as our example.
Phase 1: Discoverability
Discoverability measures how likely an LLM is to recommend your product when a developer asks for something in your category. It doesn't require any interaction with your docs or product — it's purely about what's in the model's training data and how confidently the model associates your name with relevant use cases.
Rating scale
| Score | What it means |
|---|---|
| 4/4 | Recommended as the top choice for several relevant prompts |
| 3/4 | Recommended as one of the top 3 choices, but not #1, for several relevant prompts |
| 2/4 | Mentioned when asked for more options or alternatives, but not a top choice |
| 1/4 | LLM doesn't know about it and won't recommend unless asked directly by name |
How to test it
Run a series of prompts that a developer in your target audience might plausibly send to an agent. Start broad, then narrow toward your category. Keep the session fresh — no prior context that might prime the model. Use three to five prompts per session and repeat across a couple of different models.
The prompts should mimic genuine, early-stage intent:
- A generic, open question about the problem space
- A more specific question that names the constraints (open source, event-driven, etc.)
- A request for alternatives to the obvious choices
If your product doesn't appear until prompt three, that's not discoverability — that's the model politely acknowledging you exist.
Kestra's discoverability: 2/4
We ran a three-prompt session using Claude Code as a stand-in for a developer agent starting a new project.
Prompt 1: "What's a good orchestration platform for me to use?"
Kestra doesn't appear. The model asks clarifying questions and then lists Airflow, Prefect, Dagster, Kubernetes, and LangGraph as primary recommendations. Kestra is absent from the first response entirely.
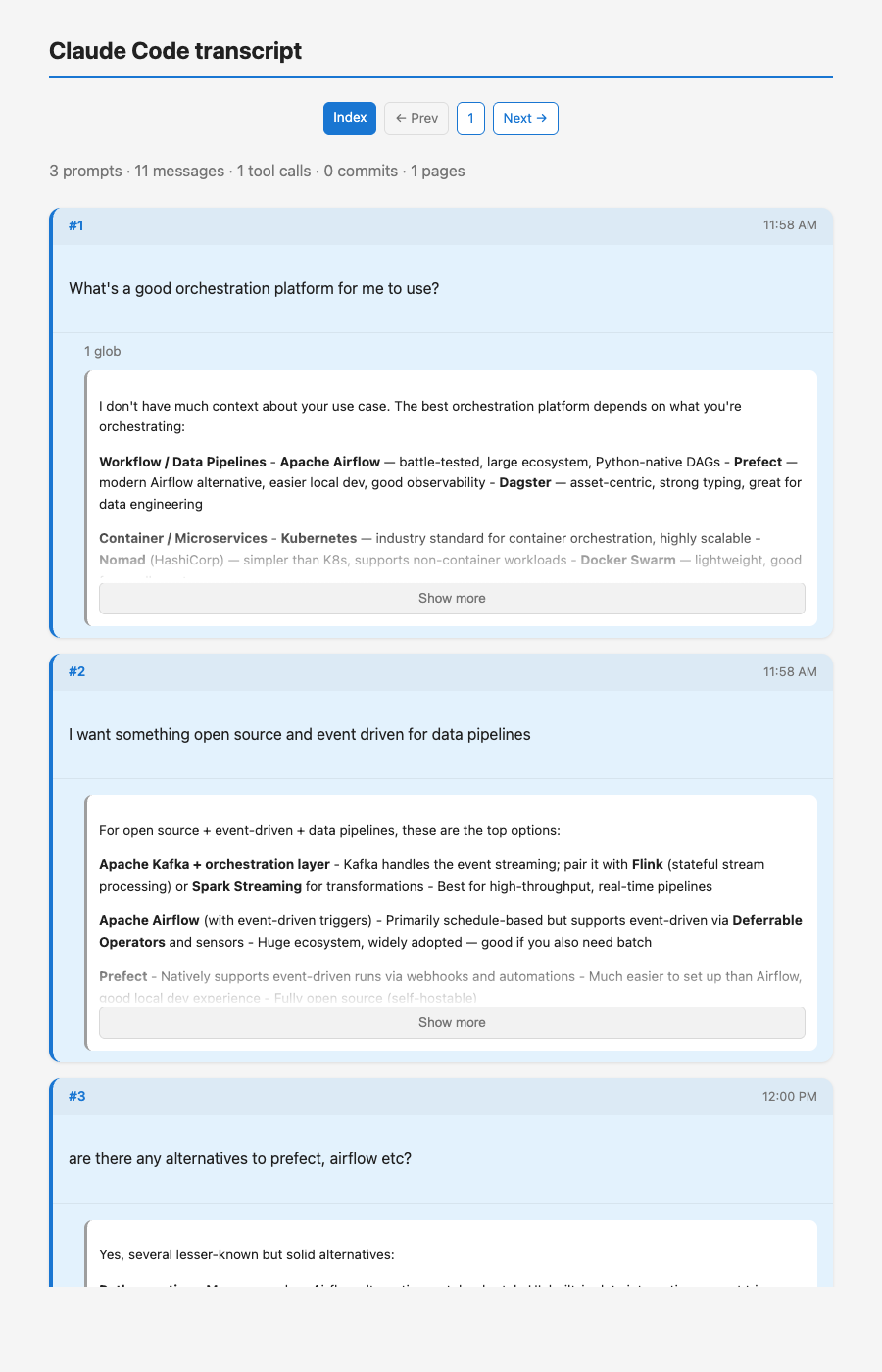
The index view of our test session. Note that the first two prompts — the broad and the narrowed question — get responses that don't mention Kestra at all.
Prompt 2: "I want something open source and event driven for data pipelines"
Still no Kestra. The response lists Kafka + Flink, Apache Airflow with deferrable operators, Prefect, Dagster, and Temporal. These are all reasonable choices, and the model explicitly recommends Prefect and Dagster as its top two. Kestra is nowhere in this list despite being a direct match for the stated constraints.
Prompt 3: "Are there any alternatives to Prefect, Airflow etc?"
Kestra finally appears — under the "event-driven focused" category, alongside Windmill and Flyte. The response also calls Kestra out again in a "worth highlighting" summary at the end. But it took an explicit request for alternatives to surface it.

The response to "are there any alternatives?" is the first time Kestra appears. It's listed as a solid option — but the developer had to know to ask.
What this means in practice
A developer using an agent to start a new orchestration project will not naturally land on Kestra. They'll get pointed to Airflow, Prefect, or Dagster. If they follow that recommendation — which most people do, because agents make it feel like a considered choice — Kestra doesn't get a look in.
The only path to Kestra via an agent, right now, is if the developer already has a reason to ask for alternatives. That's a high bar. It's the difference between being on the shortlist and being the answer someone reaches when they're already dissatisfied with the shortlist.
Kestra scores 2/4 for discoverability.
What a 4/4 looks like by comparison
For context: if you ask the same sequence of prompts about workflow orchestration for Python, Airflow and Prefect come up as top-tier recommendations at every stage. Prefect in particular gets named as a top-2 pick in response to broad, narrowed, and alternatives-seeking prompts alike. That's what owning a category feels like from the LLM's perspective.
Kestra is well-known enough to exist in the training data and be described accurately when mentioned. The gap isn't knowledge — it's association. The model knows what Kestra is; it just doesn't reach for it first.
The remaining phases — Onboarding, Integration, and Agent Tooling — are covered in the next sections.